东南亚的人工智能法规:你需要了解的风险、罚款及其他一切
努力分清自愿性与强制性规定,是任何首席技术官或产品负责人的关键。

本文由AI辅助翻译
如果您在东南亚构建或部署人工智能,可能有人曾递给您一堆“人工智能治理框架”并要求您遵守。这些框架大多是自愿性的,不带任何惩罚,但另一些则可能招致高额罚款。
这些强制性框架涵盖了从现有数据保护法到新的人工智能法规,以及您应已熟悉的行业特定规则。
努力分清自愿性与强制性规定,是任何首席技术官或产品负责人的关键。混淆两者会浪费初创公司通常不具备的宝贵时间和金钱。
作为一名为东南亚环境构建人工智能系统的应用科学家,我多年来一直从事技术方面的工作,而这些工作正是监管机构现在试图管理的领域,例如训练数据、模型文档、偏见测试和部署监督。对于构建者而言,理解这些法规的实际要求以便采取行动至关重要。
哪些情况会受罚
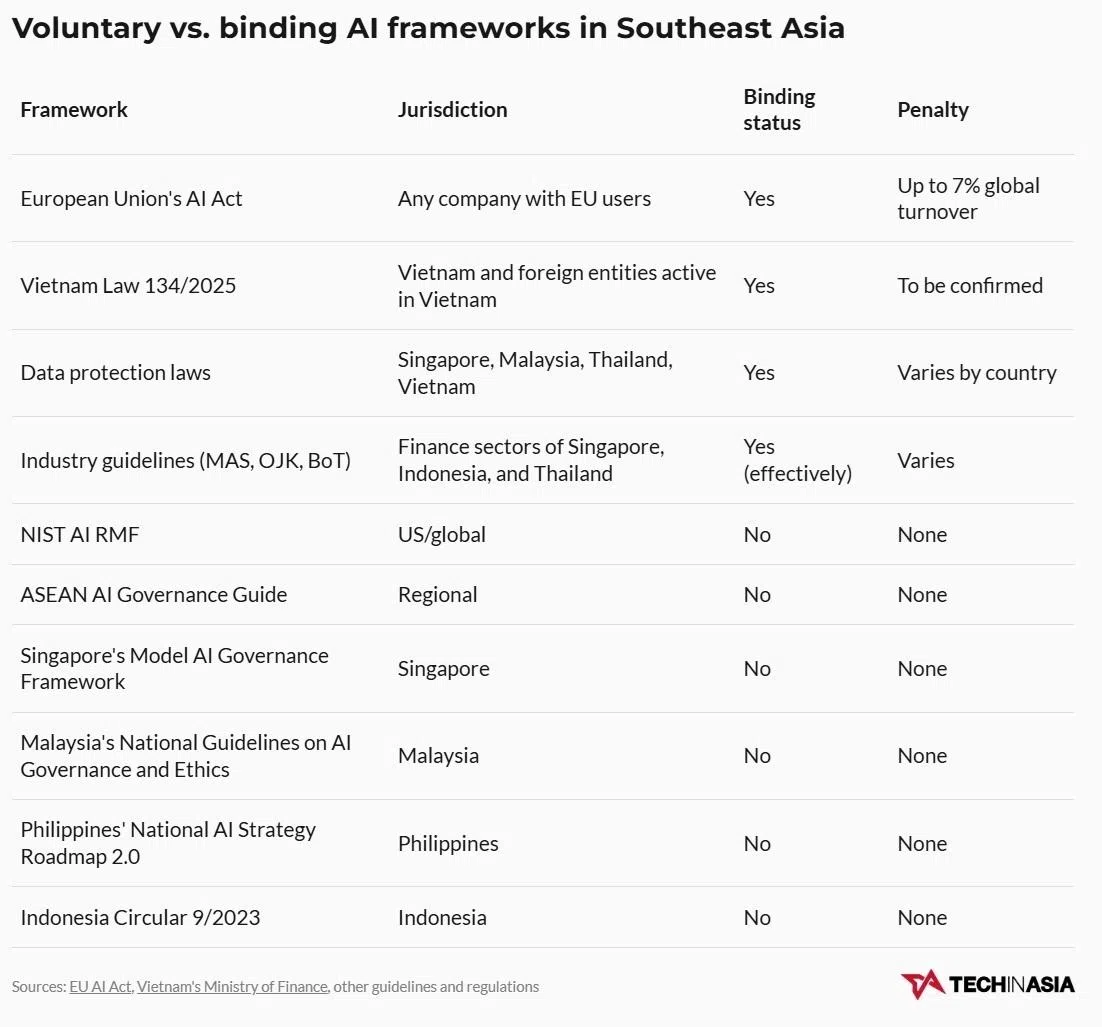
许多人工智能法规,包括欧盟的《人工智能法案》和越南的《人工智能法》,都采用基于风险的分类系统。这些法规覆盖范围广泛,涵盖了从事人工智能活动的本地和外国实体。
例如,在公共场所进行社会评分和实时生物识别被欧盟和越南都归为禁止类别。
其次是高风险级别,大多数人工智能构建者会发现自己处于这个级别。如果您的产品涉及招聘、信用评分、医疗保健、教育或基本公共服务,请默认将其视为高风险。
欧盟《人工智能法案》
第2024/1689号法规是一项具有约束力的法律,不仅适用于欧盟内部的公司,也适用于任何在欧盟以外、其人工智能系统输出在欧盟管辖范围内被使用的提供商或部署者。如果您的公司位于雅加达,但客户在柏林的办公室使用您的工具,您同样受到该法规的管辖。
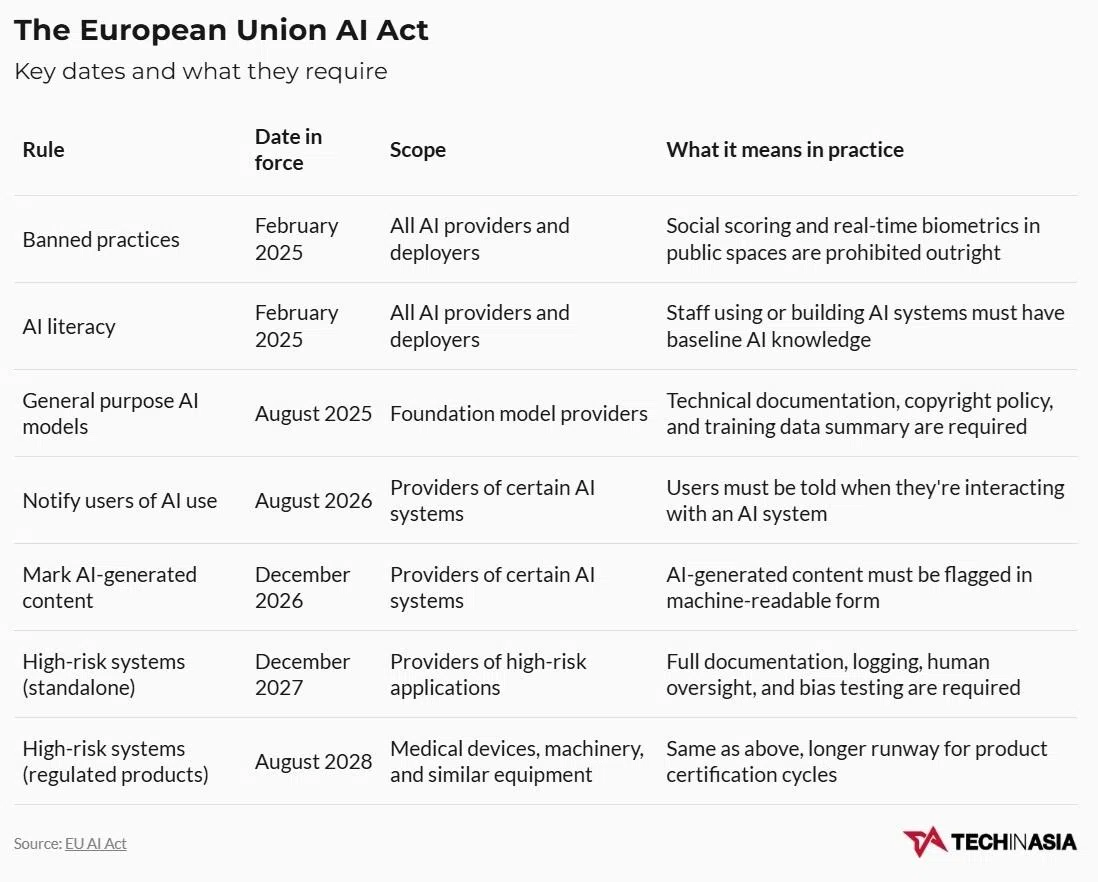
罚款并非象征性的:对于被禁止的用途,罚款最高可达3500万欧元(约合5220万新元)或全球营业额的7%;对于高风险应用的违规行为,罚款最高可达1500万欧元或全球营业额的3%。
SEE ALSO







越南《人工智能法》
第134/2025号法律并未引起许多在东南亚运营的开发团队的注意。越南国会于2025年12月10日通过了该地区首个独立、全面的人工智能法规,并于3月1日生效。
该法律的结构在很大程度上借鉴了欧盟《人工智能法案》的逻辑:同样设置了禁止、高风险和低风险等级,并对高风险系统的提供商和部署者规定了不同的义务。
根据不同行业,现有系统将获得12至18个月的过渡期。如果您向越南销售产品,那么这将是您首先需要面对的监管制度。
现行数据保护法
当您的系统处理个人信息时,即使没有专门的人工智能法律,您也同样受到监管。
新加坡、马来西亚、泰国和越南的数据保护法都带有惩罚性条款,并且全部适用于处理此类数据的人工智能系统。如果您的模型训练数据或决策涉及可识别身份的个人,那么您就面临风险。
金融监管机构
在金融领域,即使规则被标记为“指南”,实际上也具有强制性。印度尼西亚金融监管机构 Otoritas Jasa Keuangan (OJK) 已针对银行和金融科技公司发布了人工智能治理期望,其中包括2025年4月的《银行业人工智能治理指南》。
Monetary Authority of Singapore 已为金融机构设定了人工智能风险预期, 而 Bank of Thailand (BoT) 在2025年9月发布了其《金融服务提供商人工智能风险管理指南》,该指南适用于金融机构和支付服务提供商。
目前是自愿性的
除少数例外,主导讨论的框架大多不具约束力。然而,自愿性并不意味着您可以忽视它们。
一方面,企业采购越来越需要遵循此类指南。在任何法律强制要求之前,银行或政府买家就会询问您的系统是否符合自愿性框架。
更重要的是,今天的自愿性标准可能成为未来的强制性文本,团队在规划时应将此考虑在内。
高风险在实践中意味着什么
一个关键的区别决定了您的公司需要承担多大的监管负担:如果您在现有的人工智能模型之上构建产品——例如,一个基于 ChatGPT 构建的招聘工具——那么该产品的合规负担由您承担,而不是 OpenAI。大多数东南亚初创公司都处于这种情况,即使他们自己从未训练过模型。
在实践中,根据欧盟的《人工智能法案》、越南的《人工智能法》以及印度尼西亚和泰国已提出的法律草案,一个高风险系统需要在其整个生命周期中维持一个风险管理流程。
此外,还需要数据治理记录以证明您的训练数据具有相关性并经过偏见测试;需要提供外部评估员可读的技术文档;自动日志需保留至少六个月;需要明确的人工监督机制以及产品发布后的市场监控。
这是一个庞大的组合要求,必须在产品开发阶段就内置其中,而不是在发布后才附加。
正是在这一点上,地区性数据鸿沟——即东南亚语言、文化和背景在人工智能训练数据中代表性不足的问题——不再仅仅是一个伦理话题,而演变成一个合规问题。欧盟《人工智能法案》第10条要求,训练、验证和测试数据必须与预期目的相关,并具有充分的代表性。
我的解读是,如果系统要对印度尼西亚、菲律宾或越南用户做出决策,那么代表性必须延伸到他们。如果您的模型主要基于西方的、英语的数据进行训练,而您无法证明其在这些用户身上的表现,那么这项代表性测试将很难通过。
像 SEA-VL 这样的区域性数据集项目在此具有实际意义:有记录的、具有区域代表性的数据正成为合规证据的一部分。(利益披露:我是这个视觉语言数据集的合著者之一。)
未来12个月该做什么
我认为东南亚的人工智能公司可以采取四个步骤:
- 将您推出的每一款人工智能产品与适用法规中概述的风险等级进行对应。任何涉及招聘、信贷、生物识别、健康、教育或公共服务的产品都应被视为高风险。
- 如果任何产品输出会触及欧盟,请将欧盟《人工智能法案》作为您的合规底线,并按照其高风险要求进行构建。这可能是您将面临的最严格的制度,满足其要求通常也能满足其他体系的要求。
- 使用美国国家标准与技术研究院的人工智能风险管理框架 (NIST AI RMF) 或 ISO/IEC 42001 作为您的文档模板。它们是自愿性的,但与越南已生效及其他地区正在起草的强制性要求高度契合。
- 从今天开始建立审计追踪。确保您记录风险日志、训练数据来源、偏见测试结果和人工监督设计。
令人鼓舞的是,这些措施会对那些精心构建产品的团队给予回报。那些将文档记录、数据溯源和监督视为工程任务而非文书工作的人工智能公司,将能以大致相同的努力通过所有监管制度。
这张版图并不简单,但可以解读,现在就读懂它远比在审计时再来研究要划算得多。TECH IN ASIA
Vicky Feliren 是一名应用科学家,也是印度尼西亚 Monash University 的理学硕士候选人,研究方向为可信赖的多模态人工智能和视觉语言模型。
Decoding Asia newsletter: your guide to navigating Asia in a new global order. Sign up here to get Decoding Asia newsletter. Delivered to your inbox. Free.
Share with us your feedback on BT's products and services
TRENDING NOW

Singapore Kitchen CEO, senior manager charged with alleged fraud, falsifying accounts; both to stay in jobs for now

Vingroup’s shares surge 1,000% to overtake regional heavyweights including Singtel and JD.com

Johor property old hand KSL readies family handover amid market boom

Yeo’s, Tiger Beer and now Gardenia – flight of food manufacturing from Singapore might be just as planned